Benchmarking and Performance Tuning FDTD on AWS
In this article, we will explain how to benchmark computer hardware in terms of its FDTD simulation speed, how to choose a simulation representative of your common workflow, as well as the simulation-specific factors affecting simulation speed. To learn about the hardware factors that affect simulation speed, see: Information on Hardware Specifications
Measuring Performance
The most useful information for measuring performances is “time to run FDTD simulation” which is the real-time required to run the simulation, and “total FDTD solver speed on N processes” which is measured in mNodes/s (millions of nodes/cells/mesh-points per second).
This information can be found at the end of the solver log file (eg. benchmark_small_p0.log) upon completion of the simulation or after pressing “Quit and Save” from the job manager. This file is created by running the simulation and will be in the same location as the simulation file.
Additional information can be included in the log file: the “-fullinfo” flag, when passed to the FDTD solver will provide a more detailed breakdown of where time is being spent in the simulation. The “-logall” flag can be added to generate a log file for each FDTD process (eg. benchmark_small_p0.log, benchmark_small_p1.log, benchmark_small_p2.log…).
Since the 2022 R1 release, performance metrics are also provided as a result of the FDTD object, making it easier to extract this information. In addition to the simulation file used here, we also provide the script that automates the resource setup and result collection.
Choosing a simulation
Not all simulations will run at the same speed. There are many factors that will affect a simulation's run-time: 2D/3D, monitors, sources, complex materials, size, etc. It is important to pick a few representative simulations and only compare results from identical simulations.
For our tests, we used 2 simulation files:
- CMOS image sensor (
benchmark_small.fsp): The file requires about 5GB of RAM and runs in about 10-15 minutes on a 32-core desktop computer - Metalens (
benchmark_large.fsp): The file requires about 50GB of RAM and runs in about 2h on a 32-core desktop computer.
In these tests, we used the default setting to let the simulations terminate by reaching the default auto-shutoff level of 10-5. See this post for more information on the auto shutoff level.
Amazon EC2 instance types
Amazon Elastic Cloud Compute (EC2) allows to setup and run your own Virtual Machines (instances). Various instance types are available, based on hardware configurations optimized for different use cases.
- For information on EC2 pricing, see: Amazon EC2 instance pricing
- For more information on EC2 instance types, see: Amazon EC2 instance type
Intel Xeon processors
- C6i instances are the latest generation of Compute-optimized instances, powered by 3rd generation Intel Xeon Scalable processors.
- M5 instances are the latest generation of General Purpose Instances powered by Intel Xeon Platinum 8175M processors. This family provides a balance of compute, memory, and network resources, and is a good choice for many applications.
- C5 instances are the previous generation of Compute-optimized instances powered by 2nd generation Intel Xeon Scalable processors.
AMD EPYC processors
- C6a instances are the latest generation of Compute-optimized instances, powered by 3rd generation AMD EPYC 7003 processors
- C5a instances are the previous generation of Compute-optimized instances, powered by 2nd generation AMD EPYC 7002 processors
Simulation results - single simulation
For each instance type, the tests were run on Windows Server 2016 and Linux (CentOS 7.9), using:
- Windows: Microsoft MPI, Intel MPI
- Linux: MPICH2, Intel MPI
The choice of OS and/or MPI implementation didn’t show any significant impact in terms of performance. Likewise, enabling hyperthreading didn’t bring any major improvement.
Processor binding (-affinity) option was used on Windows, with Microsoft MPI. This option can improve simulation performance when running on computers with multiple CPU’s and large numbers of cores.
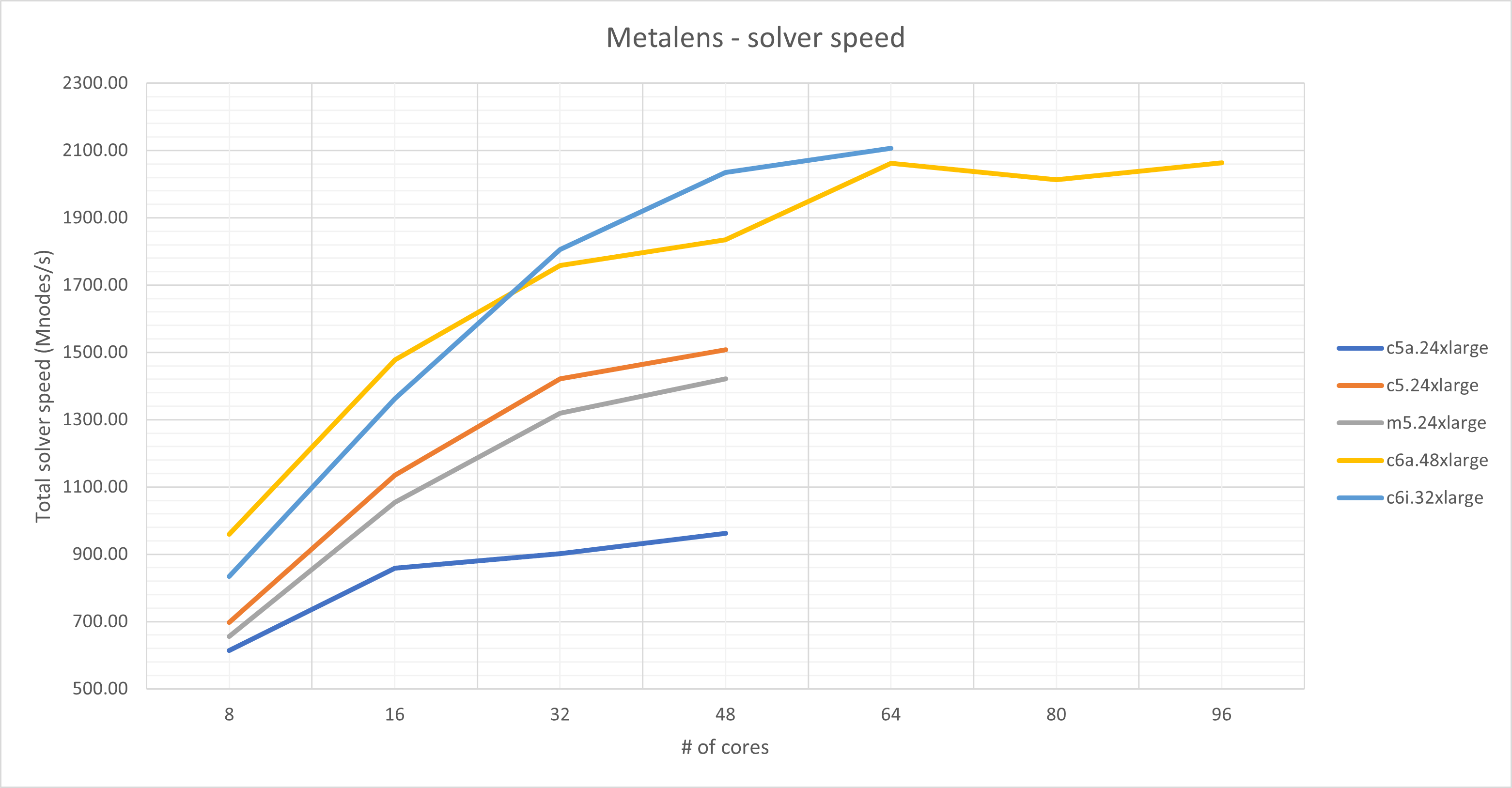
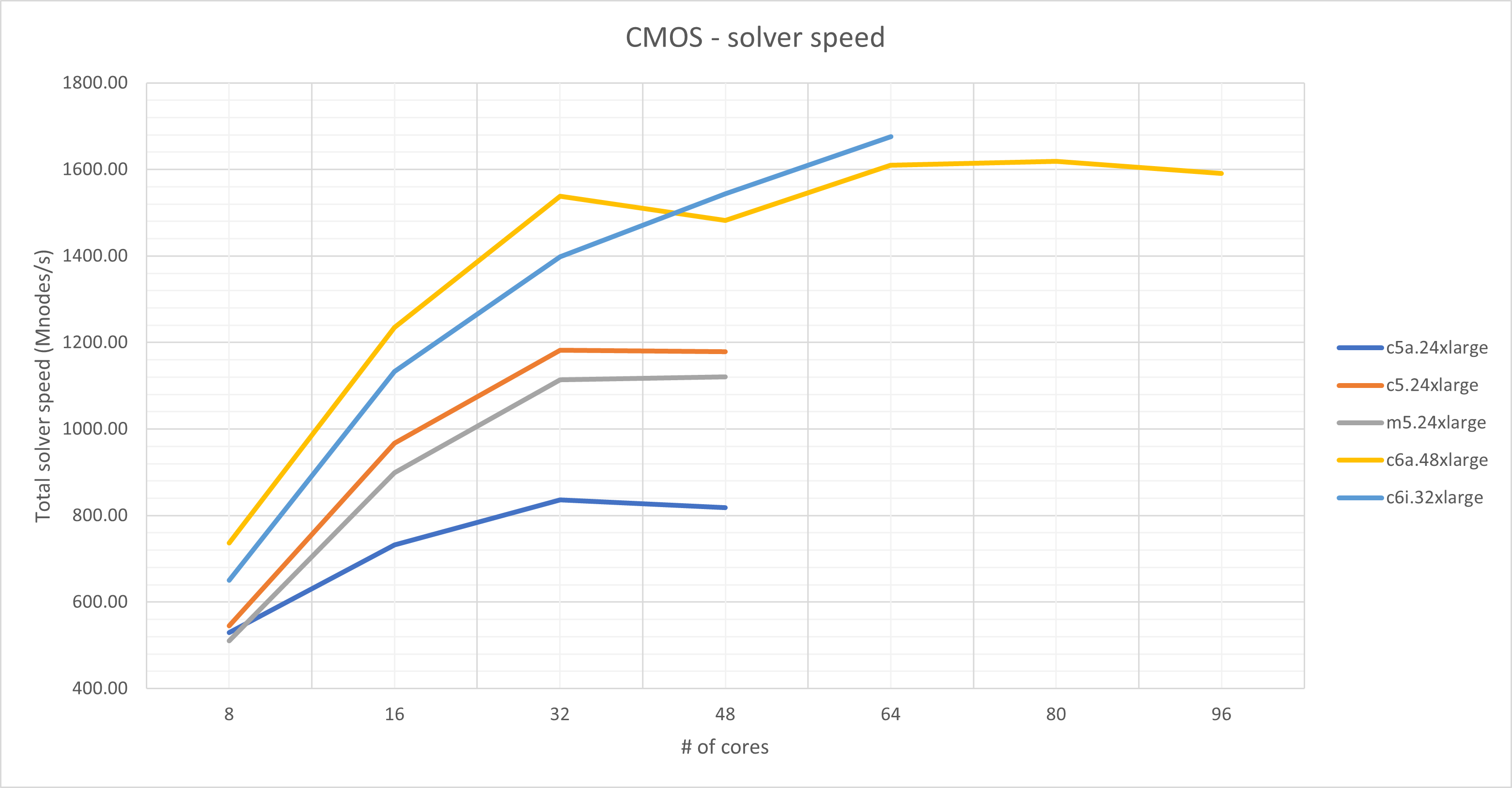
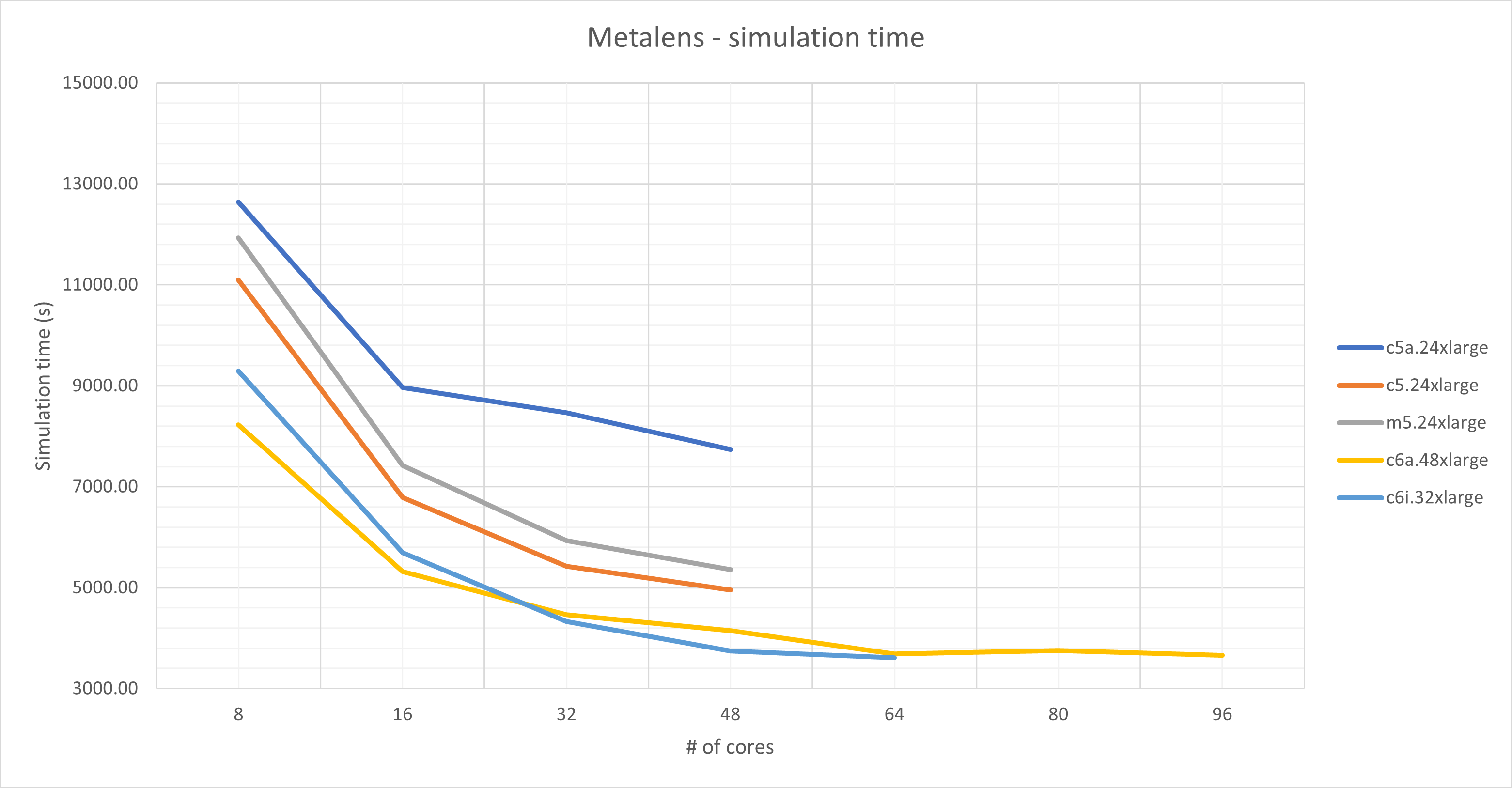
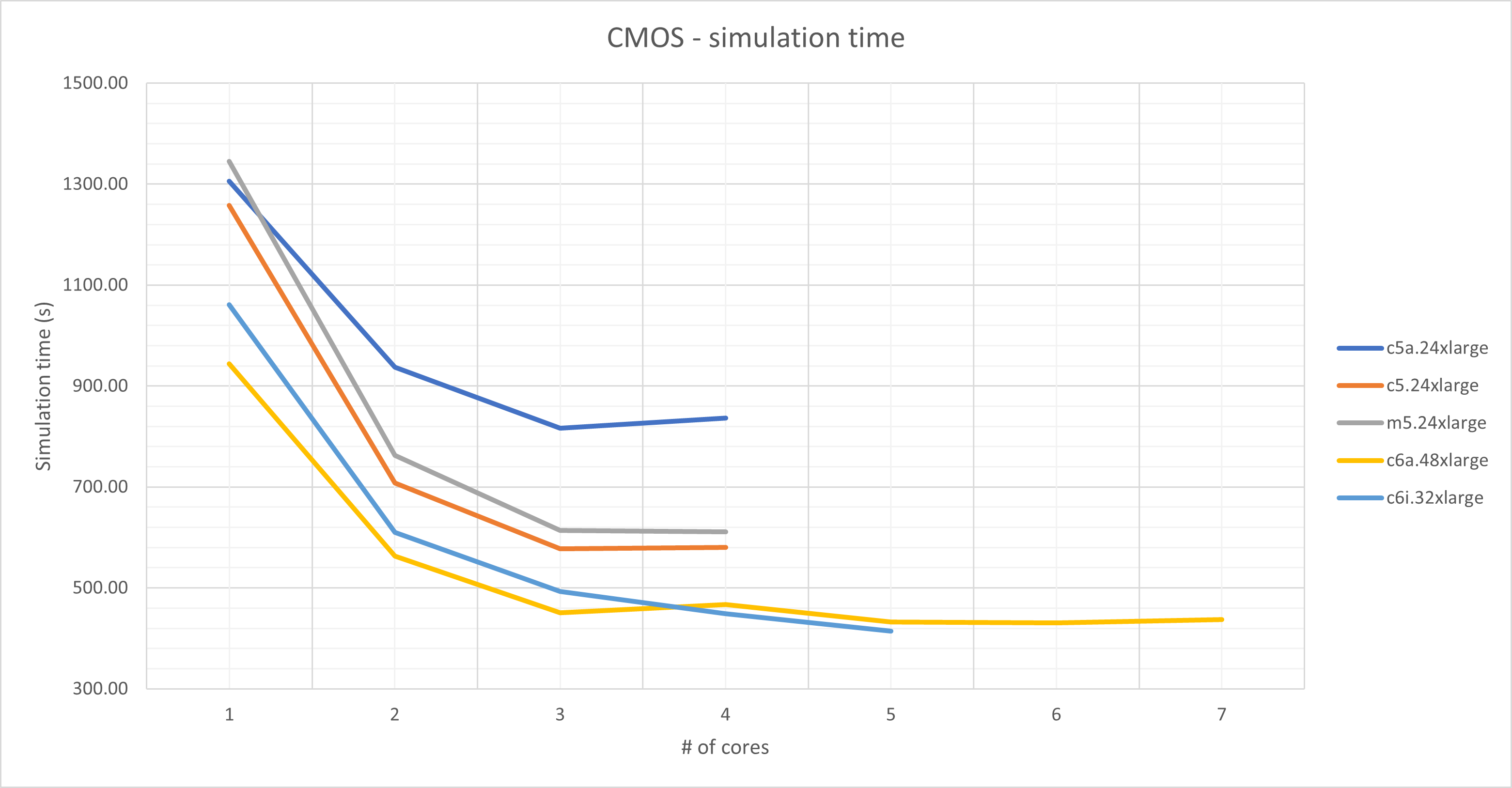
| Instance type | Description | Total solver speed (mNodes/s) | Simulation time | ||
| Metalens | CMOS | Metalens | CMOS | ||
| c6i.32xlarge |
Intel Xeon Scalable 8375C 2.9GHz 64 cores / 2 sockets 256GB RAM |
2106.1 | 1676.3 | 1h00mn | 6mn54s |
| c6a.48xlarge |
AMD EPYC 7R13 2.65GHz 96 cores / 4 sockets 384GB RAM |
2062.8 | 1590.2 | 1h01mn | 7mn18s |
| m5.24xlarge |
Intel Xeon Platinum 8172M 2.5GHz 48 cores / 2 sockets 384GB RAM |
1421.8 | 1120.8 | 1h29mn | 10mn11s |
| c5.24xlarge |
Intel Xeon Scalable 8275CL 3GHz 48 cores / 2 sockets 192GB RAM |
1508.4 | 1179.2 | 1h23mn | 9mn40s |
| c5a.24xlarge |
AMD EPYC 7R32 2.8GHz 48 cores / 1 socket 192GB RAM |
962.1 | 818.7 | 2h03mn | 13mn59s |
Summary
Simulation results - concurrent simulations
For smaller simulations, and when many calculations are required (for instance when running a parameter sweep), it might be worth using a large instance and run multiple simulations concurrently. In this section, we looked at the total solver speed and simulation time when running multiple CMOS simulations on the same instance.
| Instance type | Description | # of simulations | Cumulated solver speed (mNodes/s) | Simulation time |
| c6i.32xlarge |
Intel Xeon Scalable 8375C 2.9GHz 64 cores / 2 sockets 256GB RAM |
8 (8 core each) | 2097.7 | 44mn |
| c6a.48xlarge |
AMD EPYC 7R13 2.65GHz 96 cores / 4 sockets 384GB RAM |
12 (8 core each) | 1475.5 | 1h34mn |
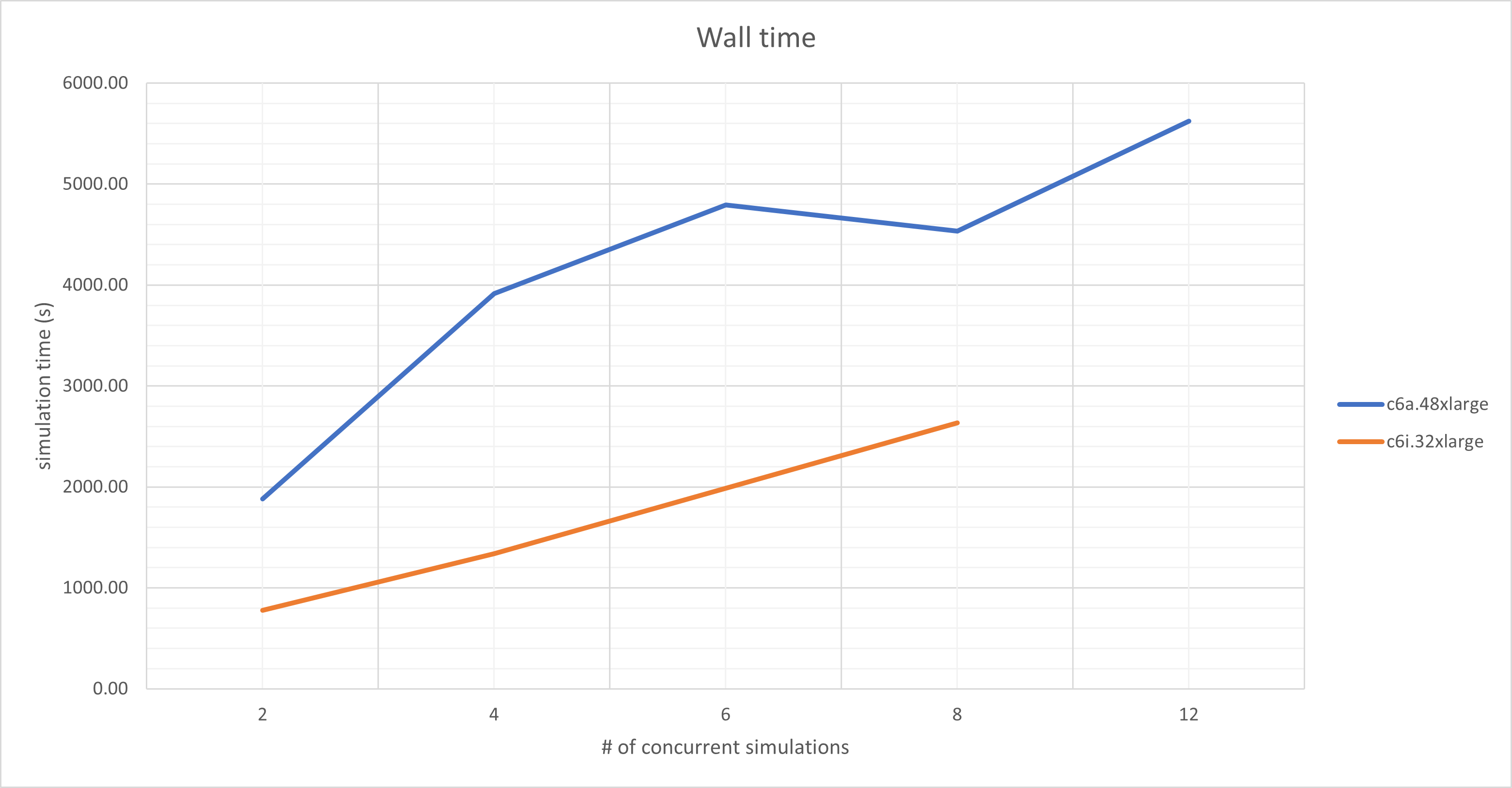
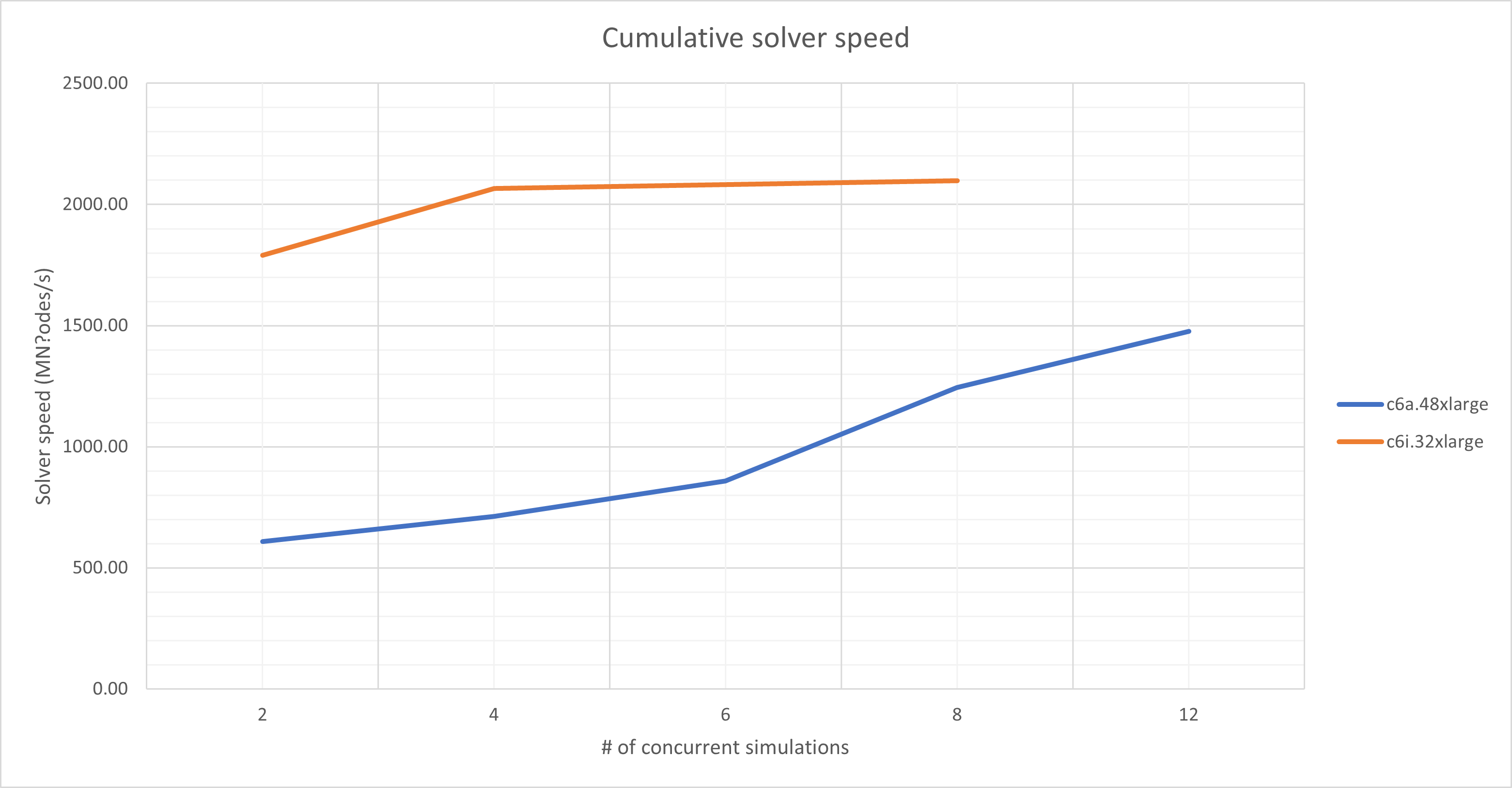
If we look at the CMOS simulation using the c6i.32xlarge instance:
- Running 1 simulations on 64 cores: 414.7s
- Running 8 simulations sequentially: 8 x 414.7 = 3317.6s
- Running 8 simulations concurrently: 2633.9s
This represents a gain of 11mn. This might not be a lot on 8 simulations, it may be a substantial gain when you have hundreds of simulations to run.
Automating benchmarking
These tests were done using the script run_benchmark.lsf. The setresource - Script command allows to modify the calculation resource. We used it to set the number of processes but also the MPI variant. A cell array is used to store the MPI configuration:
config = cell(2);
config{1} = { "name": "MSMPI", "settings": cell(1) };
config{1}.settings{1} = { "name": "job launching preset",
"value": "Remote: Microsoft MPI" };
config{2} = { "name": "IMPI", "settings": cell(1) };
config{2}.settings{1} = { "name": "job launching preset",
"value": "Remote: Intel MPI" };
The code above shows the configuration on Windows, where both Intel MPI and Microsoft MPI are provided with Lumerical.
Any resource property can be updated this way. Update "settings": cell(1) to the number of properties you want to update. For each of them, provide "name" and "value".
for(i=1:length(config)) {
?config{i}.name;
data = struct;
sim_time = total_speed = matrix(length(njob));
for(j=1:length(config{i}.settings)) {
setresource("FDTD", 1, config{i}.settings{j}.name, config{i}.settings{j}.value);
}
...
}
Notes
In this benchmark, we looked at the performance as a function of the number of processes used to run the simulation. Typically, the simulation speed will increase as more processes are used. However, at some point, the system memory bandwidth will limit any further speed increases. Beyond this point, using more processes will not improve the performance, and may in fact lead to slightly lower performance. This is evident in the CMOS image sensor simulations.
The above examples are not intended to be endorsements of the models or brands mentioned. They are simply used to illustrate the points described in the page.