
Motivation
Photonic integrated circuits are becoming increasingly complex with higher device density and integration. Typically, several competing design constraints need to be balanced such as performance, manufacturing tolerances, compactness etc. Traditional design cycles involved systematically varying a small set of characteristic parameters, simulating these devices to determine their performance and iterating to meet design requirements. Although this process is straightforward even an experienced designer struggles with their intuition once you introduce more than a few design parameters. To overcome human limitations a clever engineer may employ mathematical methods to begin anticipating strong candidates and more quickly converge on a satisfactory design.
Let us consider gradient descent optimization; we can think of the parameters as coordinates in a design space, and the figure of merit as a function of these parameters represented by a surface in this space. First, we need to define a figure of merit that encapsulates the performance of our design. Theoretically, this could be anything, but as you will see we restrict ourselves to considering only power transfer in guided mode optics. Although, we do not know what the figure of merit surface looks like beforehand we can calculate it for a given set of parameters using a physics simulator such as FDTD. Here we see what the FOM surface of two parameters might look like.
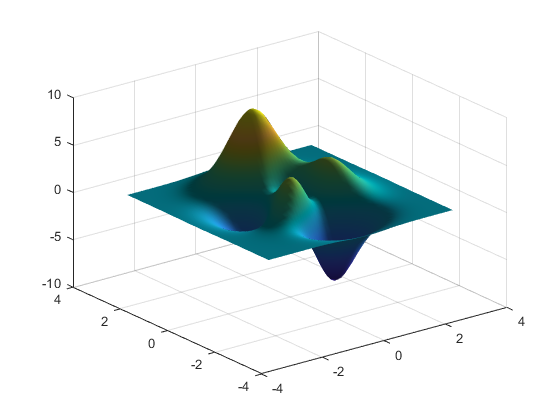
Figure 1: Figure of Merit surface
To plot an analytic function of two parameters it is straightforward to define a structured grid and calculate the output at each point; however, in our framework, each FOM calculation requires a computationally expensive simulation. Sweeping two parameters we could crudely map the FOM, but there is no guarantee that we have resolved important features, as the following figure illustrates.
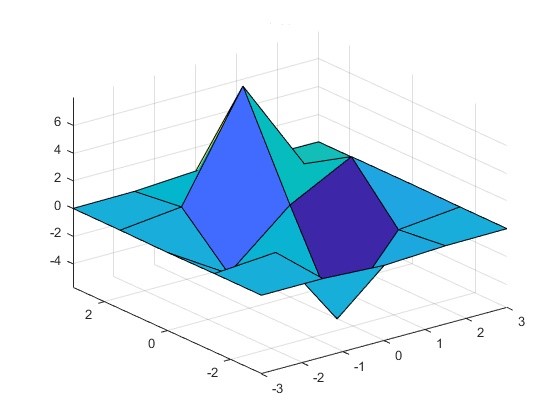
Figure 2: Undersampled parameter space
Ultimately our goal is to find an ‘optimal’ solution, and systematically calculating the surface is unnecessarily expensive; furthermore, this process becomes intractable when the dimension of our space scales up to 10, 100, or 1000s of parameters. If instead, we introduced some overhead to calculate the gradients at each function call, we can determine the next set of parameters more carefully, and in this way, we take a shorter path to find the best solution. 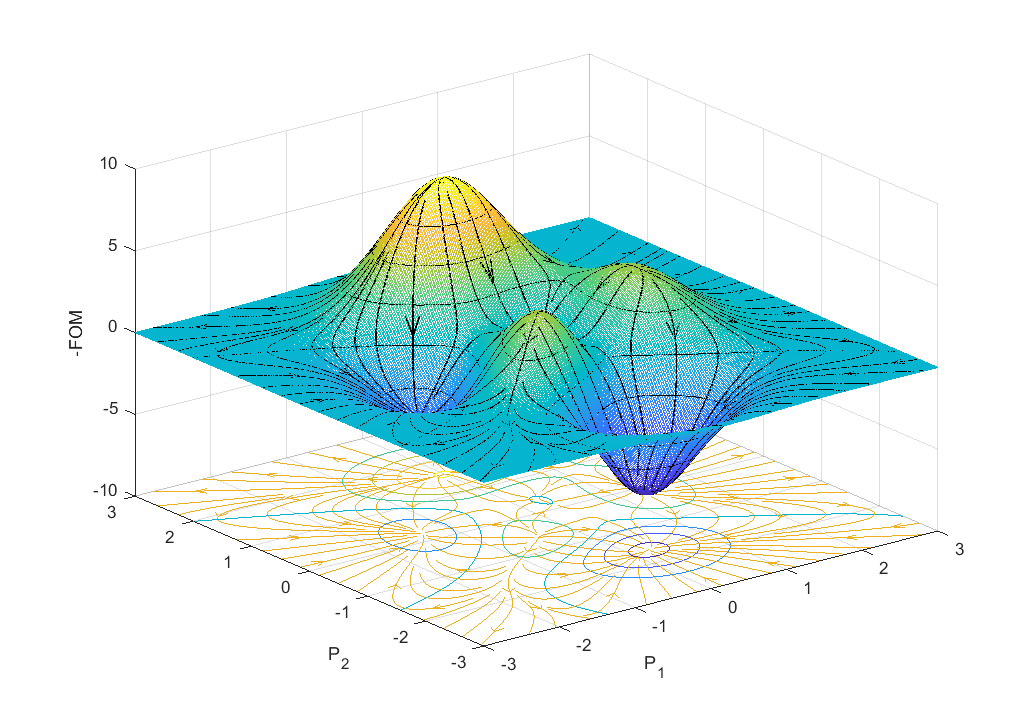
Figure 3: Gradient descent streamlines
Figure 3 illustrates the gradient of the function using streamlines. The optimizer will move in the direction of the streamline, but we have not considered other important factors like step-size or preconditioning. Notice the local minima serve as collectors based on the starting position; yet, some starting positions will not reach these minima such as those along the edge of a ridge. In our implementation, we minimize the FOM, often called the cost function, which is equivalent to maximizing the FOM. For a further discussion on gradient descent methods please see the following articles.
- Gradient Descent: All you Need to Know
- Intro to optimization in deep learning: Gradient Descent
- Scipy Tutorial on Mathematical Optimization
Adjoint Method
Using gradient descent requires finding the partial derivatives with respect to each parameter by varying each individually to get a finite difference approximation of the local derivative. At each step, this results in 1+2N simulations which introduces some overhead but is more efficient than mapping the entire space. It should be noted that once we have an FOM defined we could use any heuristic optimization technique, but at this point, we present some higher mathematics that provides an elegant solution to the problem. Consider the gradient of the FOM with respect to the parameters.
$$ \nabla_{p} F=\left(\frac{\partial F}{\partial p_{1}}, \cdots, \frac{\partial F}{\partial p_{N}}\right) $$
The adjoint state method allows us to efficiently calculate the gradient regardless of the number of parameters. Using integration by parts the original differential equations are recast in terms of the dual space. This has the powerful advantage of requiring only two simulations, forward and adjoint, to calculate the gradient.
In FDTD, the general electromagnetics problem is described by a governing system of linear algebraic equations.
$$A(p) \mathbf{x}=\mathbf{b}(p)$$
Here \( A \) contains Maxwell's equations, as well as the material permittivity and permeability of the underlying structures at each discretized point in space. The vector \( \mathbf{x} \) describes all the fields in the simulation region, and \( \mathbf{b} \) contains the free currents or equivalently the sources. The figure of merit function we have described above, is a function of design parameters, yet a more physically intuitive picture would be to consider \( F(p) = F(\mathbf{x}(p)) \).
$$\frac{\partial F}{\partial p}=\frac{\partial F}{\partial \mathbf{x}} \frac{\partial \mathbf{x}}{\partial p}$$
If we find how the FOM varies as a function of the fields and determine the sensitivity of the fields to changes in the parameters we will know the gradient. FDTD will return \( \partial F/ \partial \mathbf{x} \) through the initial forward simulation, but to find how the fields change with each of the parameters \( \partial \mathbf{x} / \partial p \) we must return to the governing equation. Taking the partial derivative with respect to p, we find the expression.
$$A \frac{\partial \mathbf{x}}{\partial p}=\frac{\partial \mathbf{b}}{\partial p}-\frac{\partial A}{\partial p} \mathbf{x}$$
Recall that b is the illumination so \( \partial \mathbf{b} / \partial p \) is the change in illumination as the parameters change. The term \( ( \partial A / \partial p )\mathbf{x} \) can be considered the change to the geometry as a result of changing the parameters. This expression for \(\partial \mathbf{x} / \partial p\) does not actually reduce our costs much, but by introducing a vector \( \mathbf{v}^{T} \) the entire equation to reduces to a scaler equality.
$$ \mathbf{v}^{T} A \frac{\partial \mathbf{x}}{\partial p}=\mathbf{v}^{T}\left(\frac{\partial \mathbf{b}}{\partial p}-\frac{\partial A}{\partial p} \mathbf{x}\right) $$
Although, this simplifies the problem we still need to specify this vector \( \mathbf{v}^{T} \). If we require that \(\mathbf{v}^{T} A=\partial F / \partial \mathbf{x}\) we immediately obtain the quantity of interest, the design sensitivity.
$$\frac{\partial F}{\partial p}=\mathbf{v}^{T}\left(\frac{\partial \mathbf{b}}{\partial p}-\frac{\partial A}{\partial p} \mathbf{x}\right)$$
The implication of the above expression is that we can calculate the gradient using exactly two simulations. From the forward simulation, we get the fields, \( \mathbf{x} \) of the simulation volume, which arise due to the defined sources, \( \mathbf{b} \), in the presence of an optimizable geometry. We support a figure of merit that is calculated as the power through an aperture projected onto the field profile of a specified mode. In the adjoint simulation, the source is replaced with the adjoint source which takes the place of the FOM monitor. The resulting fields are again recorded everywhere in the optimization region to calculate \( \mathbf{v} \) which can be conceptualized as a time-reversal simulation to find the adjoint Maxwell’s equations.
$$A^{T} \mathbf{v}=\frac{\partial F^{T}}{\partial \mathbf{x}}$$
For a more rigorous derivation and further information please see the following excellent resources.
- Adjoint shape optimization applied to electromagnetic design, Optics Express 2013 Vol. 21, Issue 18(2013)
- Optimizing Nanophotonics: from Photorecievers to Waveguides (THESIS), Christopher Lalau-Keraly
Lumopt - Shape vs Topology
This paradigm shift in the design cycle of passive photonic components we often refer to as Inverse Design. For this scheme to work the engineer provides the following:
- Simulation setup
- Parameterization of the design
- Figure of merit
- Reasonable starting point including footprint and materials
Once initialized the optimizer automatically traverses the higher dimensional design space, explores novel designs, and converges on devices with excellent performance. Furthermore, implemented techniques to bound solutions within manufacturable constraints and include performance considerations at process corners.
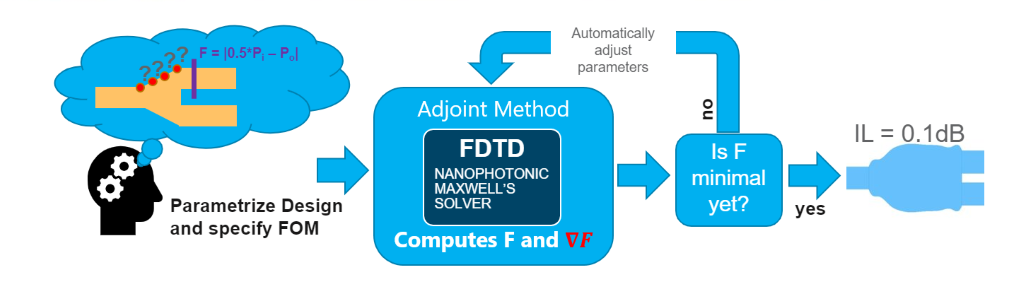
The adjoint methods outlined above are packaged as a python module called lumopt, which uses Lumerical FDTD as a client to solve Maxwell’s equations and scipy libraries to perform the optimization. The initial efforts were undertaken by Christopher Keraly, and this formulation is documented under Lumopt Read the Docs. There are some differences between the version hosted on Github and the lumopt module that ships with the Lumerical installer. We refer to the bundled Lumerical version here exclusively although there are many commonalities. Using this lumopt framework will require a solver license and an API license.
Lumopt comes in two different flavors - shape and topology optimization. With shape optimization one directly defines the geometry parameters to vary, and the bounds of these parameters. For example, the coordinates along the edge of a y-splitter. This allows the user to take a design from a good initial starting point and improve upon it; however, it takes a bit of work to define the geometry and the set of solutions which can be realized with this parameterization may be restrictive. Explicit parameterization like this means that the design rules for manufacturability can be easily enforced.
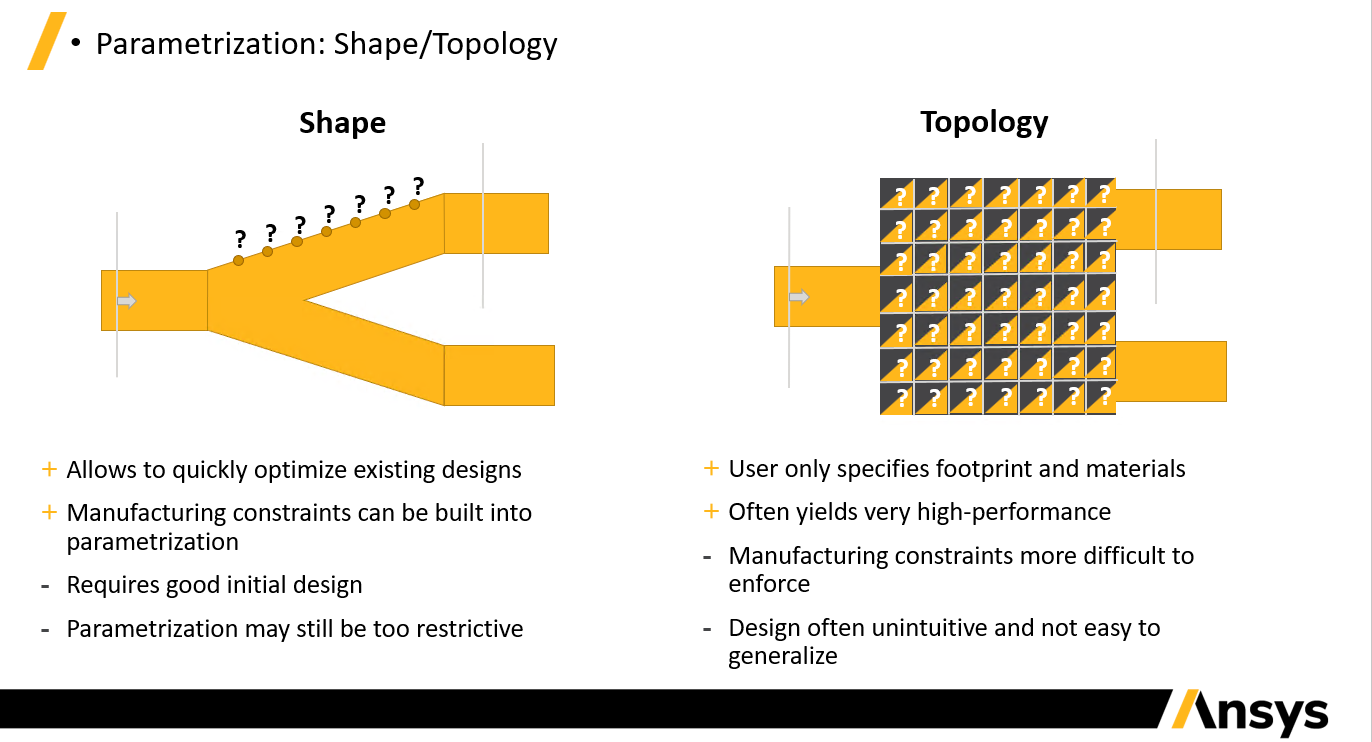
Topological inverse design requires users to simply define an optimizable footprint and the materials involved. As a result, the parameters are simply the voxels of this region which allows for very unintuitive shapes to be realized. Often inexplicably shapes and excellent performance is achieved, yet the structures tend to be harder to fabricate with photolithography owing to the small features that arise. We have taken several measures to ensure their manufacturability including smoothing functions and penalty terms to reduce small features.
For installation and the mechanics of lumopt please see the next section.